Follow these tips to resolve common problems you might encounter when working with watsonx.ai Runtime.
Troubleshooting AutoAI
- AutoAI inference notebook for a RAG experiment exceeds model limits
- Training an AutoAI experiment fails with service ID credentials
- Prediction request for AutoAI time-series model can time out with too many new observations
- Insufficient class members in training data for AutoAI experiment
- Unable to open assets from Cloud Pak for Data that require watsonx.ai
Troubleshooting deployments
-
Batch deployments that use large data volumes as input might fail
-
Deployments with constricted software specifications fail after an upgrade
-
Creating a job for an SPSS Modeler flow in a deployment space fails
Troubleshooting AutoAI
Follow these tips to resolve common problems you might encounter when working with AutoAI.
Running an AutoAI time series experiment with anomaly prediction fails
The feature to predict anomalies in the results of a time series experiment is no longer supported. Trying to run an existing experiment results in errors for missing runtime libraries. For example, you might see this error:
The selected environment seems to be invalid: Could not retrieve environment. CAMS error: Missing or invalid asset id
The behavior is expected as the runtimes for anomaly prediction are not supported. There is no workaround for this problem.
AutoAI inference notebook for a RAG experiment exceeds model limits
Sometimes when running an inference notebook generated for an AutoAI RAG experiment, you might get this error:
MissingValue: No "model_limits" provided. Reason: Model <model-nam> limits cannot be found in the model details.
The error indicates that the token limits for inferencing the foundation model used for the experiment are missing. To resolve the problem, find the function default_inference_function and replace get_max_input_tokens with the max tokens for the model. For example:
model = ModelInference(api_client=client, **params['model"])
# model_max_input_tokens = get+max_input_tokens(model=model, params=params)
model_max_input_tokens = 4096
You can find the max token value for the model in the table of supported foundation models available with watsonx.ai.
Training an AutoAI experiment fails with service ID credentials
If you are training an AutoAI experiment using the API key for the serviceID, training might fail with this error:
User specified in query parameters does not match user from token.
One way to resolve this issue is to run the experiment with your user credentials. If you want to run the experiment with credentials for the service, follow these steps to update the roles and policies for the service ID.
- Open your serviceID on IBM Cloud.
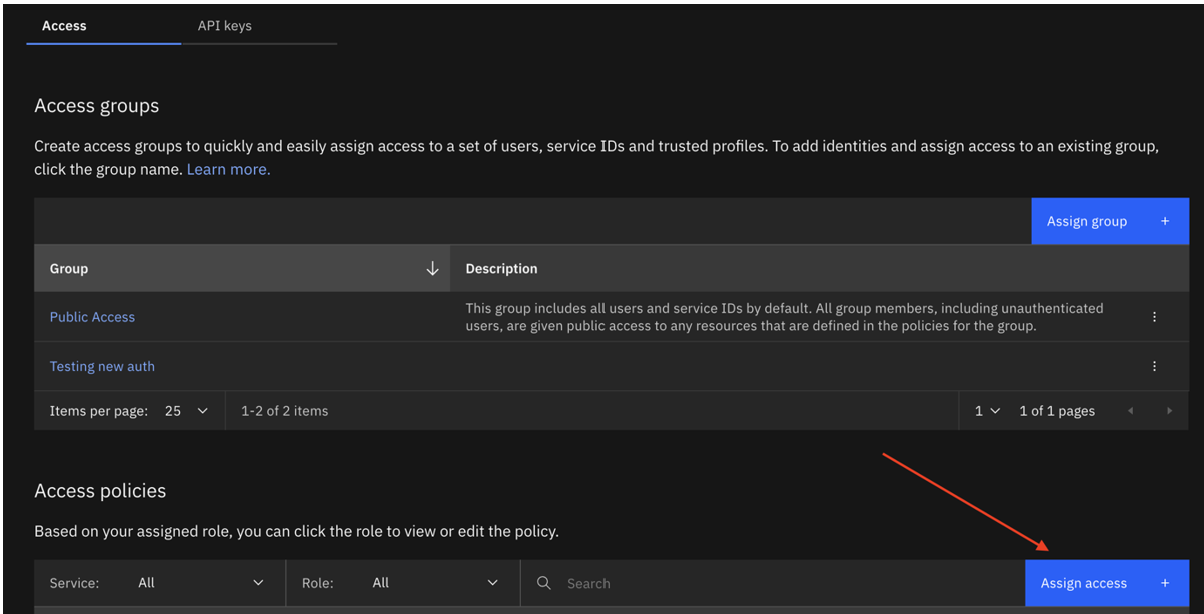
- Create a new serviceID or update the existing ID with the following access policy:
- All IAM Account Management services with the roles API key reviewer,User API key creator, Viewer, Operator, and Editor. Ideally it is best if they create a new apikey for this ServiceId.
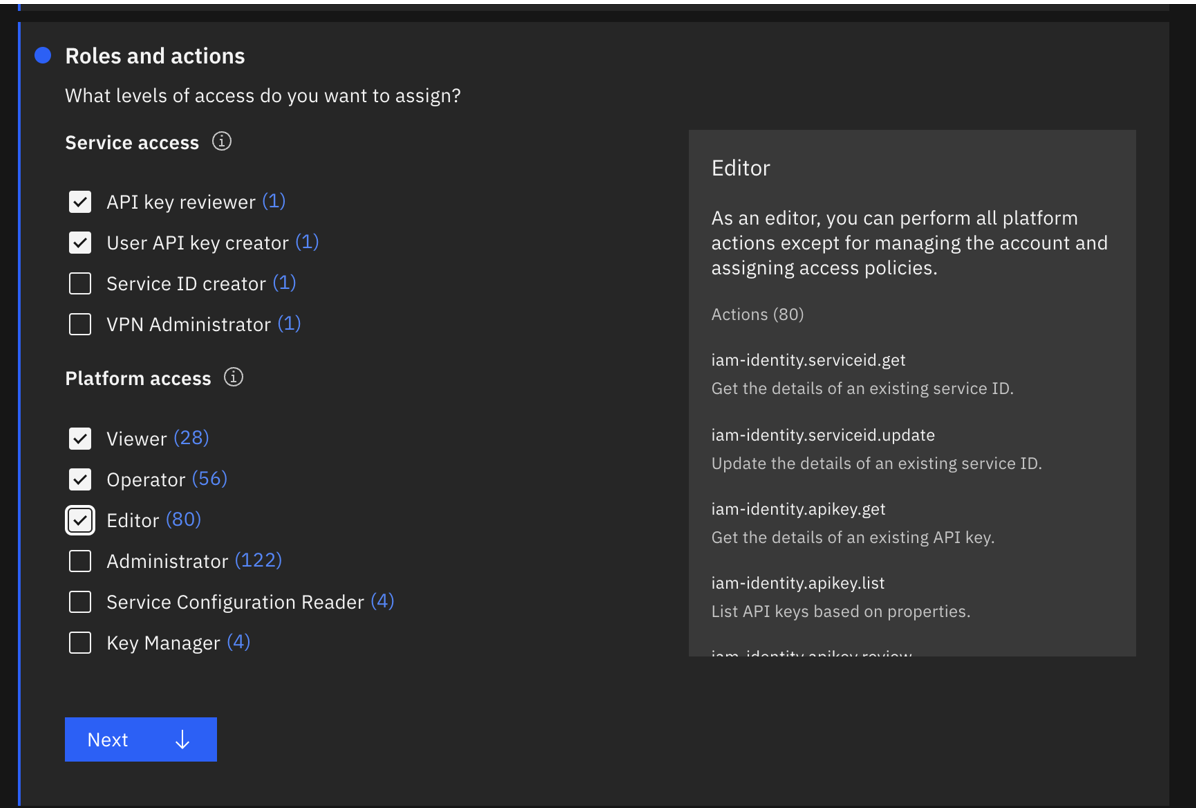
- All IAM Account Management services with the roles API key reviewer,User API key creator, Viewer, Operator, and Editor. Ideally it is best if they create a new apikey for this ServiceId.
- The updated policy will look as follows:
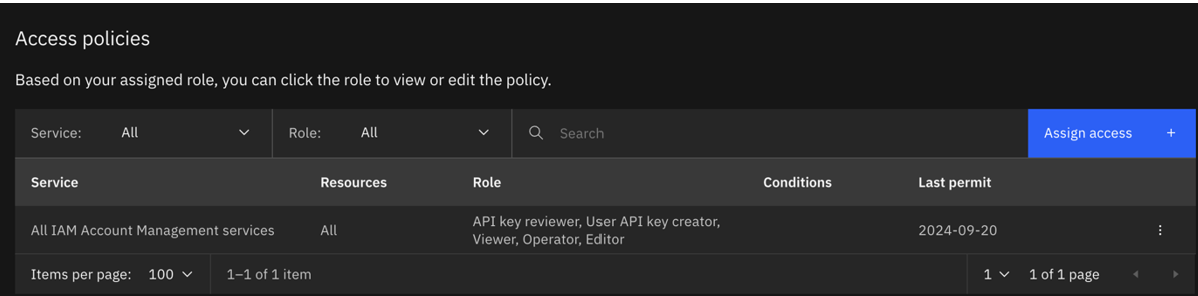
- Run the training again with the credentials for the updated serviceID.
Prediction request for AutoAI time-series model can time out with too many new observations
A prediction request can time out for a deployed AutoAI time-series model if there are too many new observations passed. To resolve the problem, do one of the following:
- Reduce the number of new observations.
- Extend the training data used for the experiment by adding new observations. Then, re-run the AutoAI time-series experiment with the updated training data.
Insufficient class members in training data for AutoAI experiment
Training data for an AutoAI experiment must have at least 4 members for each class. If your training data has an insufficient number of members in a class, you will encounter this error:
ERROR: ingesting data Message id: AC10011E. Message: Each class must have at least 4 members. The following classes have too few members: ['T'].
To resolve the problem, update the training data to remove the class or add more members.
Unable to open assets from Cloud Pak for Data that require watsonx.ai
If you are working the in the Cloud Pak for Data context, you are unable to open assets that require a different product context, such as watsonx.ai. For example, if you create an AutoAI experiment for a RAG pattern using watsonx.ai, you cannot open that asset when you are in the Cloud Pak for Data context. In the case of AutoAI experiments, you can view the training type from the Asset list. You can open experiments with type machine learning, but not with type Retrieval-augmented generation.
Troubleshooting deployments
Follow these tips to resolve common problems you might encounter when working with watsonx.ai Runtime deployments.
Batch deployments that use large data volumes as input might fail
If you are scoring a batch job that uses large volumes of data as the input source, the job might fail becase of internal timeout settings. A symptom of this problem might be an error message similar to the following example:
Incorrect input data: Flight returned internal error, with message: CDICO9999E: Internal error occurred: Snowflake sQL logged error: JDBC driver internal error: Timeout waiting for the download of #chunk49(Total chunks: 186) retry=0.
If the timeout occurs when you score your batch deployment, you must configure the data source query level timeout limitation to handle long-running jobs.
Query-level timeout information for data sources is as follows:
| Data source | Query level time limitation | Default time limit | Modify default time limit |
|---|---|---|---|
| Apache Cassandra | Yes | 10 seconds | Set the read_timeout_in_ms and write_timeout_in_ms parameters in the Apache Cassandra configuration file or in the Apache Cassandra connection URL to change the default time limit. |
| Cloud Object Storage | No | N/A | N/A |
| Db2 | Yes | N/A | Set the QueryTimeout parameter to specify the amount of time (in seconds) that a client waits for a query execution to complete before a client attempts to cancel the execution and return control to the application. |
| Hive via Execution Engine for Hadoop | Yes | 60 minutes (3600 seconds) | Set the hive.session.query.timeout property in the connection URL to change the default time limit. |
| Microsoft SQL Server | Yes | 30 seconds | Set the QUERY_TIMEOUT server configuration option to change the default time limit. |
| MongoDB | Yes | 30 seconds | Set the maxTimeMS parameter in the query options to change the default time limit. |
| MySQL | Yes | 0 seconds (No default time limit) | Set the timeout property in the connection URL or in the JDBC driver properties to specify a time limit for your query. |
| Oracle | Yes | 30 seconds | Set the QUERY_TIMEOUT parameter in the Oracle JDBC driver to specify the maximum amount of time a query can run before it is automatically cancelled. |
| PostgreSQL | No | N/A | Set the queryTimeout property to specify the maximum amount of time that a query can run. The default value of the queryTimeout property is 0. |
| Snowflake | Yes | 6 hours | Set the queryTimeout parameter to change the default time limit. |
To avoid your batch deployments from failing, partition your data set or decrease its size.
Security for file uploads
Files you upload through the watsonx.ai Studio or watsonx.ai Runtime UI are not validated or scanned for potentially malicious content. It is recommended that you run security software, such as an anti-virus application, on all files before uploading to ensure the security of your content.
Deployments with constricted software specifications fail after an upgrade
If you upgrade to a more recent version of IBM Cloud Pak for Data and deploy an R Shiny application asset that was created by using constricted software specifications in FIPS mode, your deployment fails.
For example, deployments that use shiny-r3.6 and shiny-r4.2 software specifications fail after you upgrade from IBM Cloud Pak for Data version 4.7.0 to 4.8.4 or later. You might receive the error message Error 502 - Bad Gateway.
To prevent your deployment from failing, update the constricted specification for your deployed asset to use the latest software specification. For more information, see Managing outdated software specifications or frameworks. You can also delete your application deployment if you no longer need it.
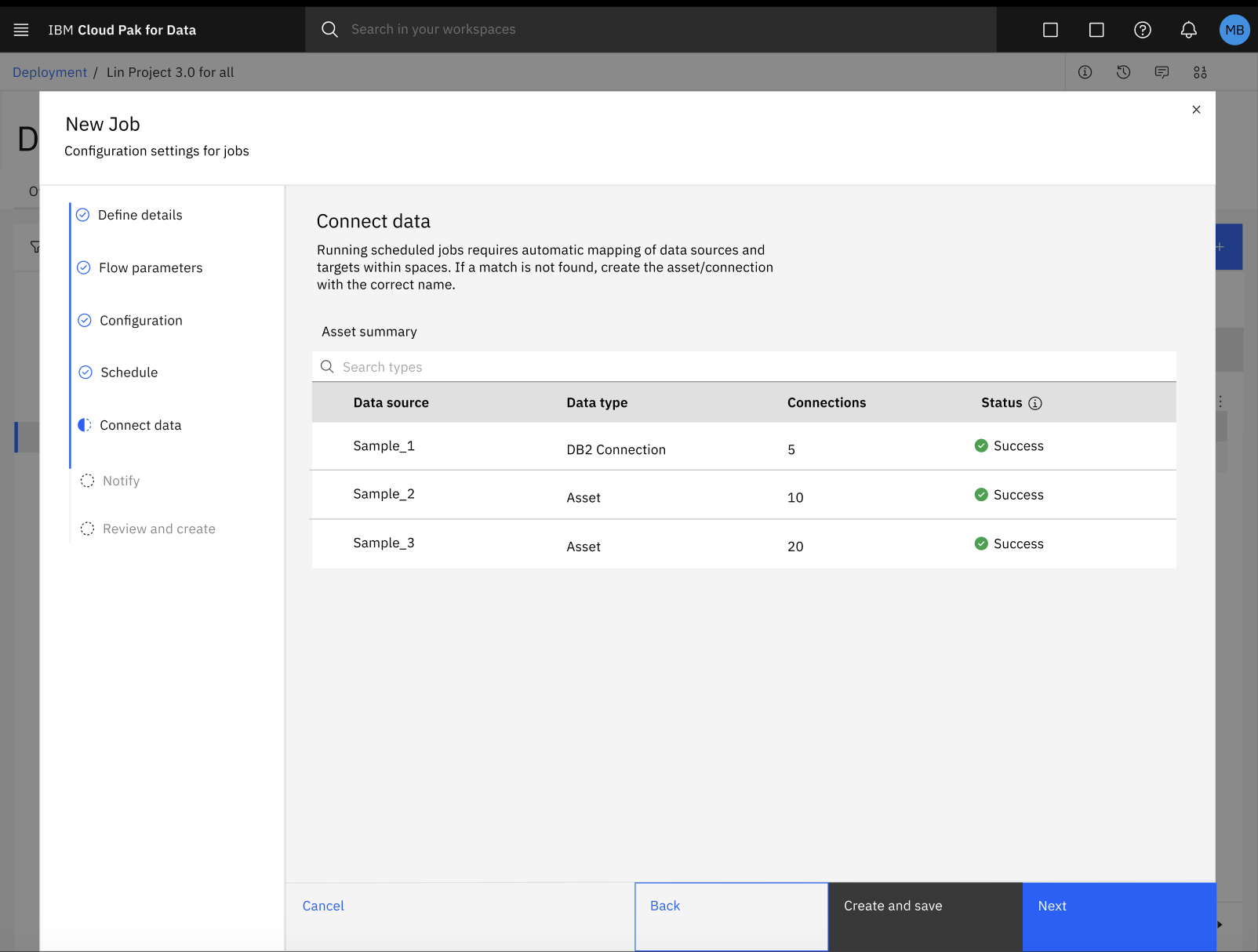
Creating a job for an SPSS Modeler flow in a deployment space fails
During the process of configuring a batch job for your SPSS Modeler flow in a deployment space, the automatic mapping of data assets with their respective connection might fail.
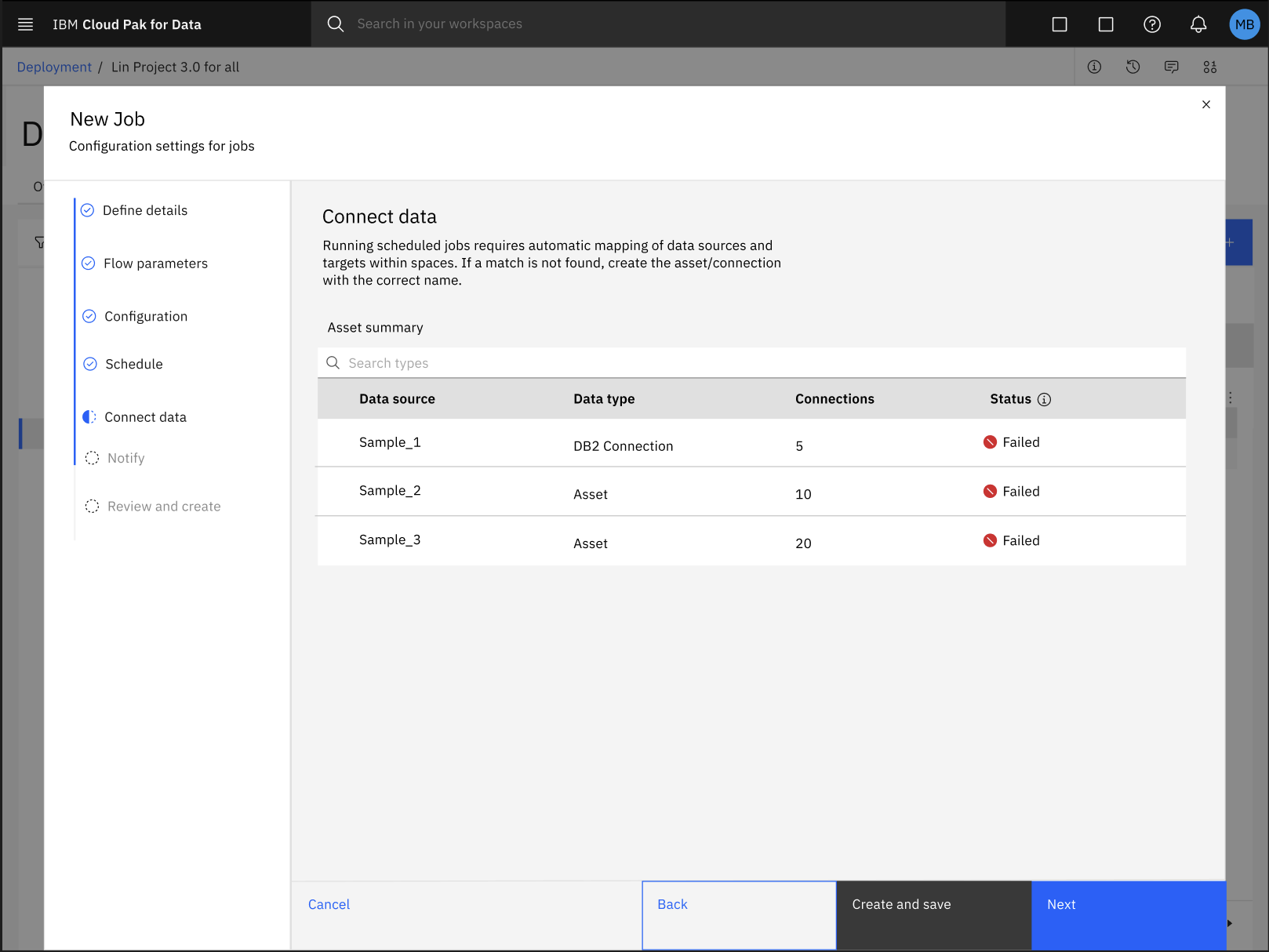
To fix the error with the automatic mapping of data assets and connections, follow these steps:
-
Click Create to save your progress and exit from the New job configuration dialog box.
-
In your deployment space, click the Jobs tab and select your SPSS Modeler flow job to review the details of your job.
-
In the job details page, click the Edit icon
 to manually update the mapping of your data assets and connections.
to manually update the mapping of your data assets and connections. -
After updating the mapping of data assets and connection, you can resume with the process of configuring settings your job in the New job dialog box. For more information, see Creating deployment jobs for SPSS Modeler flows
Converting a model from LightGBM to ONNX fails
If you use an unsupported objective function to convert your LightGBM models to ONNX format, your deployment might fail. For example, if you use an unsupported objective function in the lightgbm.Booster definition, you might have
problems with the conversion.
To resolve this problem, ensure that you use a supported objective function when you convert LightGBM models to ONNX.
The following code sample shows how to replace the unsupported objective function in the lightgbm.Booster definition with a function that is compatible with convert_lightgbm.
lgb_model = lightgbm.Booster(model_str=lgb_model.model_to_string().replace('<unsupported_objective_function>', '<compatible_objective_function>'))