Creating online deployments
Create an online deployment for machine learning models, Decision Optimization solutions, or Python functions to generate predictions or results in real time. For example, create an online deployment for a classification model that is trained to predict whether a bank customer enrolls in a promotion. Submitting new customer data to the deployment endpoint returns a prediction in real time.
Deployable asset types for online deployments
You can create online deployments for these types of assets:
- Functions
- Models
- AutoAI models
- Decision Optimization models
- Models that are imported from a file
- Models that are created with supported frameworks
- SPSS Modeler models
You cannot deploy R Shiny application assets on Cloud Pak for Data as a Service.
Ways to create an online deployment
You can create an online deployment one of these ways:
- Use a no-code approach to Create an online deployment from a deployment space.
- Use code to Create an online deployment programmatically by using notebooks.
After you create an online deployment, an endpoint URL is generated. You can use the endpoint URL to test the deployment or to include the deployment in your applications.
Before you begin
You must set up your task credentials by generating an API key. For more information, see Managing task credentials.
Creating an online deployment from a deployment space
Follow these steps to create your online deployment from a deployment space:
-
Promote or add the asset that you want to deploy to a space. For more information, see Assets in a deployment space.
-
From the Assets page, click Deploy from the action menu.
-
From the deployment details page, click New deployment.
-
Choose Online as the deployment type.
-
Provide a name and an optional description for the deployment.
-
Use the Serving name field to specify a name for your deployment instead of deployment ID.
Note:- The serving name must be distinctive within the namespace.
- The serving name must contain only these characters: [a-z,0-9,_] and must be a maximum 36 characters long.
- The serving name works only as part of the prediction URL. Sometime, you may have to use the deployment ID.
-
Optional: Select a hardware specification if you're deploying Python functions, Tensorflow models, or models with custom software specifications. For example, if you are scaling a deployment, you might want to increase the hardware resources.
Restriction:You cannot create or select custom hardware specifications from the user interface in a deployment space. To learn more about ways to create and select a hardware specification, see Managing hardware specifications for deployments.
-
Optional: Select a software specification that is compatible with your asset. You can select software specifications for functions only.
-
Click Create to create the deployment.
Testing an online deployment
Follow these steps to test your online deployment:
- From the Deployments tab of your space, click the deployment name.
- Click the Test tab to enter data and get a prediction or other response from the deployed asset.
The way that you provide test data for an online deployment depends on the type of asset you deployed. For most assets, you can directly enter test data into a form, upload a file that contains test data, or paste the test data in as JSON code. For example, following is the test interface for a classification model:
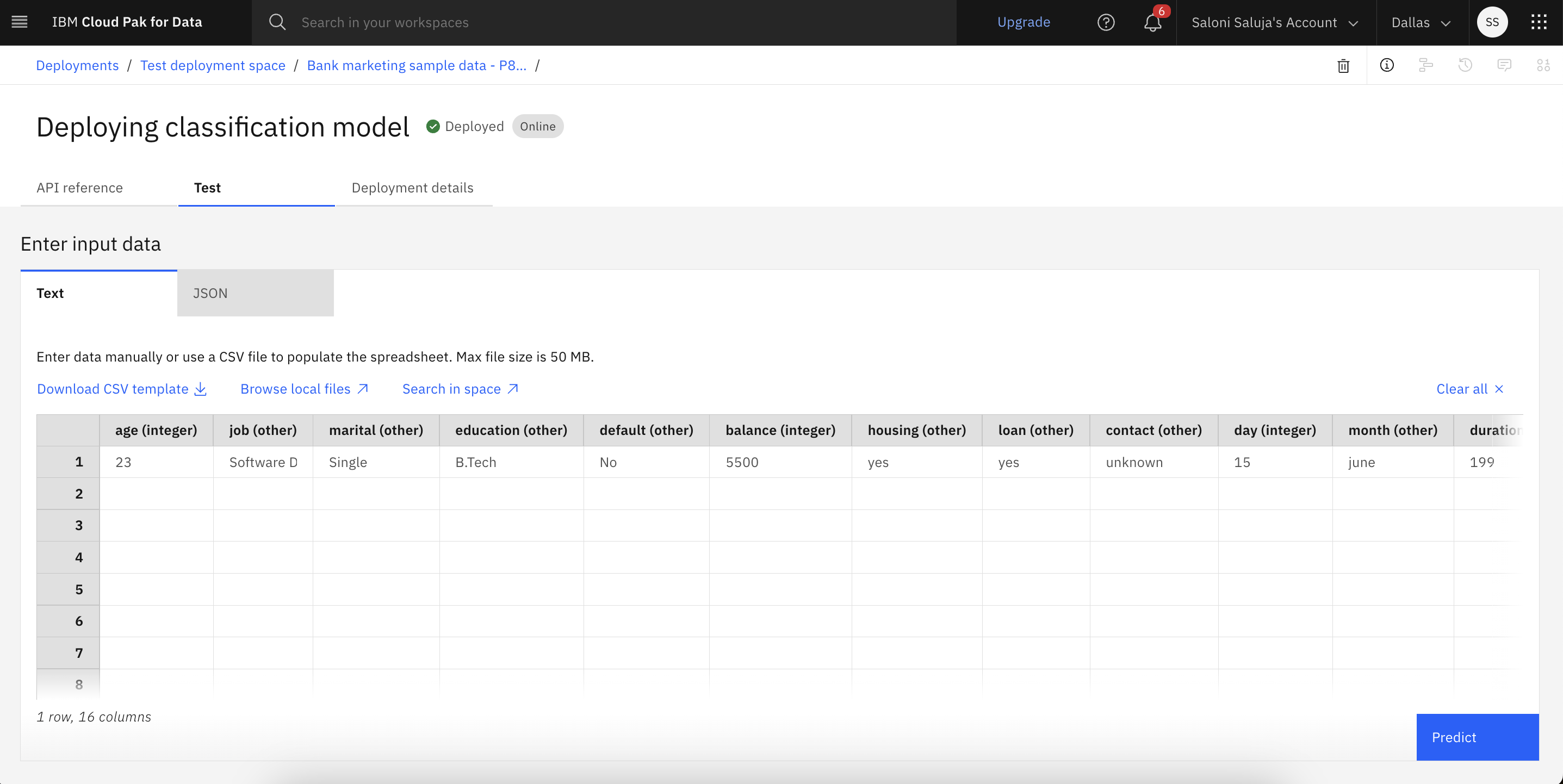
For providing test data:
- If your deployed model has a defined schema, your test data must use the same schema. For example, for a classification model, enter test data by using the same columns, omitting the prediction column.
Sample JSON code to test a deployment
When you submit JSON code as the payload, or input data, for a deployment, your input data must match the requirements of the deployed asset.
For example, for a model with a schema, the fields must match the column headers for the data, and the values must contain the data (in the same order). Use this format:
{"input_data":[{
"fields": [<field1>, <field2>, ...],
"values": [[<value1>, <value2>, ...]]
}]}
Refer to this example:
{"input_data":[{
"fields": ["PassengerId","Pclass","Name","Sex","Age","SibSp","Parch","Ticket","Fare","Cabin","Embarked"],
"values": [[1,3,"Braund, Mr. Owen Harris",0,22,1,0,"A/5 21171",7.25,null,"S"]]
}]}
For formatting JSON input:
- All strings are enclosed in double quotation marks. The Python notation for dictionaries looks similar, but Python strings in single quotation marks are not accepted in the JSON data.
- Indicate missing values with
null.
Retrieving the endpoint for an online deployment
Follow these steps to retrieve the endpoint URL for your online deployment so that you can access the deployment from your applications:
- From the Deployments tab of your space, click the deployment name.
- In the API Reference tab, find the private and public endpoint links. You can also find code snippets in various programming languages such as Python, Java, and more to include the endpoint details in an application.
If you added Serving name when you created your online deployment, you see two endpoint URLs. The first URL contains the deployment ID, and the second URL contains your serving name. You can use either one of these URLs with your deployment.
Accessing the online deployment details
Follow these steps to review or update deployment details:
- From the Deployments tab of your space, click a deployment name.
- Click the Deployment details tab to access information that is related to your online deployment.
Creating online deployment programmatically by using notebooks
You can create an online deployment programmatically by using:
- watsonx.ai Runtime REST API.
- watsonx Python client library.
To access sample notebooks that use demonstrate how to create and manage deployments by using watsonx.ai Runtime Python client, see Machine learning samples and examples.
Testing your online deployment programmatically
To test your online deployment programmatically, you must prepare a payload that matches the schema of the existing model requirements of the deployed asset. For example, the input data (payload) for a classification model must match the schema of the deployed model. The following sample for a classification model provides test data with columns and values that exactly match the model schema:
model_details = client.repository.get_details("<model_id>") # retrieves details and includes schema
columns_in_schema = []
for i in range(0, len(model_details['entity']['schemas']['input'][0].get('fields'))):
columns_in_schema.append(model_details['entity']['schemas']['input'][0].get('fields')[i]['name'])
X = X[columns_in_schema] # where X is a pandas dataframe that contains values to be scored
#(...)
scoring_values = X.values.tolist()
array_of_input_fields = X.columns.tolist()
payload_scoring = {"input_data": [{"fields": [array_of_input_fields],"values": scoring_values}]}
Retrieving the endpoint for an online deployment programmatically
To retrieve the endpoint URL of your online deployment from a notebook:
- List the deployments by calling the Python client method
client.deployments.list(). - Find the row with your deployment. The deployment endpoint URL is listed in the
urlcolumn.
Learn more
To learn how to create a batch deployment, see Creating a batch deployment.
To learn how to manage deployment jobs, and update, scale, or delete an online deployment, see Managing assets.
To learn more about deployment endpoints, see Endpoint URLs.
Parent topic: Managing predictive deployments