Creating jobs in deployment spaces
A job is a way of running a batch deployment, or a self-contained asset like a script, notebook, code package, or flow in watsonx.ai Runtime. You can select the input and output for your job and choose to run it manually or on a schedule. From a deployment space, you can create, schedule, run, and manage jobs.
Notebooks, scripts, code packages, and flows use notebook environments and do not require a batch deployment to run. To run such asset without creating a batch job, find it in the Assets tab, click the Options button, select New job, and follow the job creation steps.
Before you begin
To improve the security for running deployment jobs, task credentials are required for deployment job requests. To learn how to set up your task credentials and generate an API key, see Adding task credentials.
Creating a batch deployment job
Follow these steps to create a batch deployment job:
You must have an existing batch deployment to create a batch job. For information about creating batch deployments, see Creating batch deployments.
- From the Deployments tab, select your deployment and click New job. The Create a job dialog box opens. Follow the steps that appear in the dialog box.
- Optional: If you are deploying a Python script, an R script, or a notebook, then you can enter environment variables to pass parameters to the job. Click Environment variables to enter the key - value pair.
- Optional: To prevent resource exhaustion by keeping all of historical job metadata, follow one of these options:
- Click By amount to set thresholds for saving a set number of job runs and associated logs.
- Click By duration (days) to set thresholds for saving artifacts for a specified number of days.
- Optional: In the Schedule section, toggle the Schedule off button to schedule a run. You can set a date and time for start of schedule and set a schedule for repetition. Click Next.
Note: If you don't specify a schedule, the job runs immediately.
- Optional: In the Notify section, toggle the Off button to turn on notifications associated with this job. Click Next.
Note: You can receive notifications for three types of events: success, warning, and failure.
- In the Choose data section, provide inline data that corresponds with your model schema. You can provide input in JSON format. Click Next. See Example JSON payload for inline data.
- In the Review and create section, verify your job details, and click Create and run.
Notes:
- Scheduled jobs display in the Jobs tab of the deployment space.
- Results of job runs are written to the specified output file and saved as a space asset.
- A data asset can be a data source file that you promoted to the space, a connected data source, or tables from databases and files from file-based data sources.
- If you exclude certain weekdays in your job schedule, the job might not run as you would expect. The reason is due to a discrepancy between the time zone of the user who creates the schedule, and the time zone of the main node where the job runs.
- When you create or modify a scheduled job, an API key is generated. Future runs use this generated API key.
Example JSON payload for inline data
{
"deployment": {
"id": "<deployment id>"
},
"space_id": "<your space id>",
"name": "test_v4_inline",
"scoring": {
"input_data": [{
"fields": ["AGE", "SEX", "BP", "CHOLESTEROL", "NA", "K"],
"values": [[47, "M", "LOW", "HIGH", 0.739, 0.056], [47, "M", "LOW", "HIGH", 0.739, 0.056]]
}]
}
}
Queuing and concurrent job executions
The maximum number of concurrent jobs for each deployment is handled internally by the deployment service. For batch deployment, by default, two jobs can be run concurrently. Any deployment job request for a batch deployment that already has two running jobs is placed in a queue for execution later. When any of the running jobs is completed, the next job in the queue is run. The queue has no size limit.
Limitation on using large inline payloads for batch deployments
Batch deployment jobs that use large inline payload might get stuck in starting or running state. For more information, see
Retention of deployment job metadata
Job-related metadata is persisted and can be accessed until the job and its deployment are deleted.
Viewing deployment job details
When you create or view a batch job, the deployment ID and the job ID are displayed.
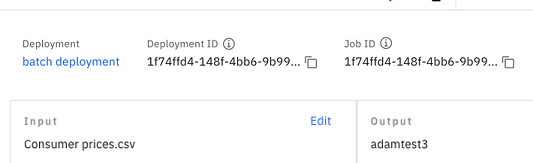
- The deployment ID represents the deployment definition, including the hardware and software configurations and related assets.
- The job ID represents the details for a job, including input data and an output location and a schedule for running the job.
Use these IDs to refer to the job in watsonx.ai Runtime Data and AI Common Core API requests or in notebooks that use the watsonx.ai Python client library.
Parent topic: Managing predictive deployments