Creating a text analysis experiment
Use AutoAI's text analysis feature to perform text analysis of your experiments. For example, perform basic sentiment analysis to predict an outcome based on text comments.
Text analysis overview
When you create an experiment that uses the text analysis feature, the AutoAI process uses the word2vec algorithm to transform the text into vectors, then compares the vectors to establish the impact on the prediction column.
The word2vec algorithm takes a corpus of text as input and outputs a set of vectors. By turning text into a numerical representation, it can detect and compare similar words. When trained with enough data, word2vec can make accurate predictions about a word's meaning or relationship to other words. The predictions can be used to analyze text and guess at the meaning in sentiment analysis applications.
During the feature engineering phase of the experiment training, 20 features are generated for the text column, by using the word2vec algorithm. Auto-detection of text features is based on analyzing the number of unique values in
a column and the number of tokens in a record (minimum number = 3). If the number of unique values is less than number of all values divided by 5, the column is not treated as text.
When the experiment completes, you can review the feature engineering results from the pipeline details page. You can also save a pipeline as a notebook, where you can review the transformations and see a visualization of the transformations.
Example: Analyzing customer comments
In this example, the comments for a fictional car rental company are used to train a model that predicts a satisfaction rating when a new comment is entered.
Watch this short video to see this example and then read further details about the text feature below the video.
This video provides a visual method to learn the concepts and tasks in this documentation.
-
Video transcript Time Transcript 00:00 In this video you'll see how to create an AutoAI experiment to perform sentiment analysis on a text file. 00:09 You can use the text feature engineering to perform text analysis in your experiments. 00:15 For example, perform basic sentiment analysis to predict an outcome based on text comments. 00:22 Start in a project and add an asset to that project, a new AutoAI experiment. 00:29 Just provide a name, description, select a machine learning service, and then create the experiment. 00:38 When the AutoAI experiment builder displays, you can add the data set. 00:43 In this case, the data set is already stored in the project as a data asset. 00:48 Select the asset to add to the experiment. 00:53 Before continuing, preview the data. 00:56 This data set has two columns. 00:59 The first contains the customers' comments and the second contains either 0, for "Not satisfied", or 1, for "Satisfied". 01:08 This isn't a time series forecast, so select "No" for that option. 01:13 Then select the column to predict, which is "Satisfaction" in this example. 01:19 AutoAI determines that the satisfaction column contains two possible values, making it suitable for a binary classification model. 01:28 And the positive class is 1, for "Satisfied". 01:32 Open the experiment settings if you'd like to customize the experiment. 01:36 On the data source panel, you'll see some options for the text feature engineering. 01:41 You can automatically select the text columns, or you can exercise more control by manually specifying the columns for text feature engineering. 01:52 You can also select how many vectors to create for each column during text feature engineering. 01:58 A lower number faster and a higher number is more accurate, but slower. 02:03 Now, run the experiment to view the transformations and progress. 02:09 When you create an experiment that uses the text analysis feature, the AutoAI process uses the word2vec algorithm to transform the text into vectors, then compares the vectors to establish the impact on the prediction column. 02:23 During the feature engineering phase of the experiment training, twenty features are generated for the text column using the word2vec algorithm. 02:33 When the experiment completes, you can review the feature engineering results from the pipeline details page. 02:40 On the Features summary panel, you can review the text transformations. 02:45 You can see that AutoAI created several text features by applying the algorithm function to the column elements, along with the feature importance showing which features contribute most to your prediction output. 02:59 You can save this pipeline as a model or as a notebook. 03:03 The notebook contains the code to see the transformations and visualizations of those transformations. 03:09 In this case, create a model. 03:13 Use the link to view the model. 03:16 Now, promote the model to a deployment space. 03:23 Here are the model details, and from here you can deploy the model. 03:28 In this case, it will be an online deployment. 03:36 When that completes, open the deployment. 03:39 On the test app, you can specify one or more comments to analyze. 03:46 Then, click "Predict". 03:49 The first customer is predicted not to be satisfied with the service. 03:54 And the second customer is predicted to be satisfied with the service. 03:59 Find more videos in the Cloud Pak for Data as a Service documentation.
Given a data set that contains a column of review comments for the rental experience (Customer_service), and a column that contains a binary satisfaction rating (Satisfaction) where 0 represents a negative comment and 1 represents a positive comment, the experiment is trained to predict a satisfaction rating when new feedback is entered.
Training a text transformation experiment
After you load the data set and specify the prediction column (Satisfaction), the Experiment settings selects the Use text feature engineering option.
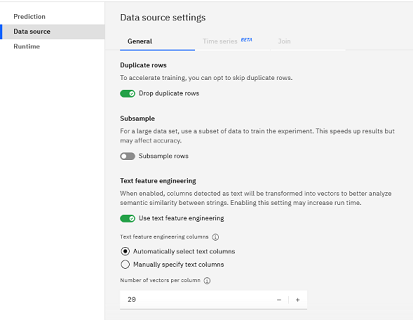
Note some of the details for tuning your text analysis experiment:
- You can accept the default selection of automatically selecting the text columns or you can exercise more control by manually specifying the columns for text feature engineering.
- As the experiment runs, a default of 20 features is generated for the text column by using the
word2vecalgorithm. You can edit that value to increase or decrease the number of features. The more vectors that you generate the more accurate your model are, but the longer training takess. - The remainder of the options applies to all types of experiments so you can fine-tune how to handle the final training data.
Run the experiment to view the transformations in progress.
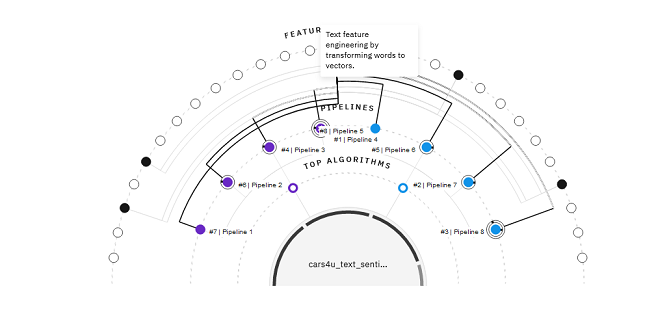
Select the name of a pipeline, then click Feature summary to review the text transformations.
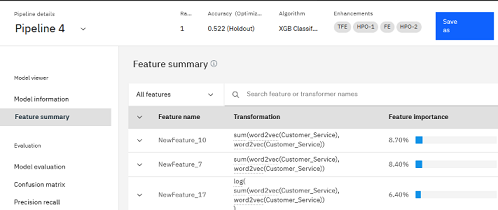
You can also save the experiment pipeline as a notebook and review the transformations as a visualization.
Deploying and scoring a text transformation model
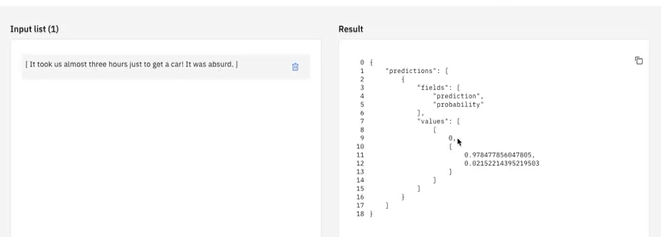
When you score this model, enter new comments to get a prediction with a confidence score for whether the comment results in a positive or negative satisfaction rating.
For example, entering the comment "It took us almost three hours to get a car. It was absurd" predicts a satisfaction rating of 0 with a confidence score of 95%.
Next steps
Building a time series forecast experiment
Parent topic: Building an AutoAI model